 |
MIDAPACK - MIcrowave Data Analysis PACKage
1.1b
Parallel software tools for high performance CMB DA analysis
|
|
MIDAPACK - MIcrowave Data Analysis PACKage
1.1b
Parallel software tools for high performance CMB DA analysis
|
Considering a matrix 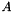 , parallelism assume is row-distributed over processes. Each processor has into memory m rows of the global matrix. Reciprocally
, parallelism assume is row-distributed over processes. Each processor has into memory m rows of the global matrix. Reciprocally 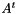 is column-distributed, with m columns into memory. That is to say
is column-distributed, with m columns into memory. That is to say
![\[ A = \left( \begin{array}{c}A_0 \\A_1\\ \vdots \\ A_{n_{prc}-1} \end{array} \right) \]](form_4.png)
Reciprocally
![\[ A^t=(A_0^t, A_1^t, A_2^t, ... A_{n_{prc}-1}^t) \]](form_5.png)
.
As is a sparse martix, it doesn't store zero values. Furthermore we assume is exactly nnz nonzerovalues. Then building matrix A only require these non-zero values and theirs global columns indices, also called ELL format. Input data consists in two large tab of size m*nnz, where rows are concatenated. This input array have to be passed when calling matrix initializtaion function.
To well ballence the load over processes we have to ensure number of rows time number of non-zero per row is roughly the same on each processor
The two following examples illustrate the input data needs to build a matrix using MatInit. The first one is a sequential, the second consider 2 processors.
![\[ A = \left( \begin{array}{ccccc}1&7&0&0&0\\0&0&2&0&8\\5&0&3&0&0\\5&0&2&0&0\\0&0&2&9&0\\0&0&0&8&6\\0&1&0&0&3\\0&6&0&4&0\end{array} \right) \]](form_42.png)
![\[ A = \left( \begin{array}{c} A_0 \\ A_1 \end{array} \right) \]](form_43.png)
![\[ A_0 = \left( \begin{array}{ccccc} 1&7&0&0&0\\0&0&2&0&8\\5&0&3&0&0\\5&0&2&0&0\end{array} \right) , A_1 = \left( \begin{array}{ccccc} 0&0&2&9&0\\0&0&0&8&6\\0&1&0&0&3\\0&6&0&4&0\end{array} \right) \]](form_44.png)
The internal structure is more sophisticated than the ELL format. Especially, to enhance matrix operations performance, a precomputation step reshapes the data structure into several arrays : global ordered columns indices, local indices, communication ...
When using MatInit function, precomputation is performed blindly. Nevertheless, for advanced user it is able to initialize a matrix in several steps. This enables to specify differents methods for the precomputations.
 1.8.1.1
1.8.1.1 
